tanuki- 2022-07-03 強化学習
実験内容
- 「tanuki- 2022-06-07 やねうら王学習部リグレッション調査」で作成した評価関数が思いのほか強かったので、そこからの強化学習を行い、レーティングの変化を測定する。
棋譜生成
| 生成ルーチン | tanuki-棋譜生成ルーチン |
| 評価関数 | https://docs.google.com/document/d/1Lup-hHFH2_QWqEfe56obJ6OEwj15P-C0VO6pWV9-vgo/edit?usp=sharing やねうら王 V5.33 で作成した評価関数 FV_SCALE=16 |
| 1手あたりの思考 | 深さ最大 9 思考ノード数最大 50,000 ノード |
| 開始局面 | foodgate の 2020 年~ 2021 年の棋譜のうち、レーティング 3900 以上同士の対局の 32 手目までから 1 局面ランダムに選択し、その局面を開始局面とした ランダムムーブなし |
| 生成局面数 | 10 億局面 × 8 セット |
| 生成条件 | 対局は打ち切らず詰みの局面まで学習データに出力した |
機械学習
| 機械学習ルーチン | やねうら王機械学習ルーチン |
| 学習モデル | halfkp_256x2-32-32 |
| 学習手法 | SGD ミニバッチ法 |
| USI_Hash | 1024 |
| Threads | 127 |
| loop | 100 |
| batchsize | 1000000 |
| lambda | 0.5 |
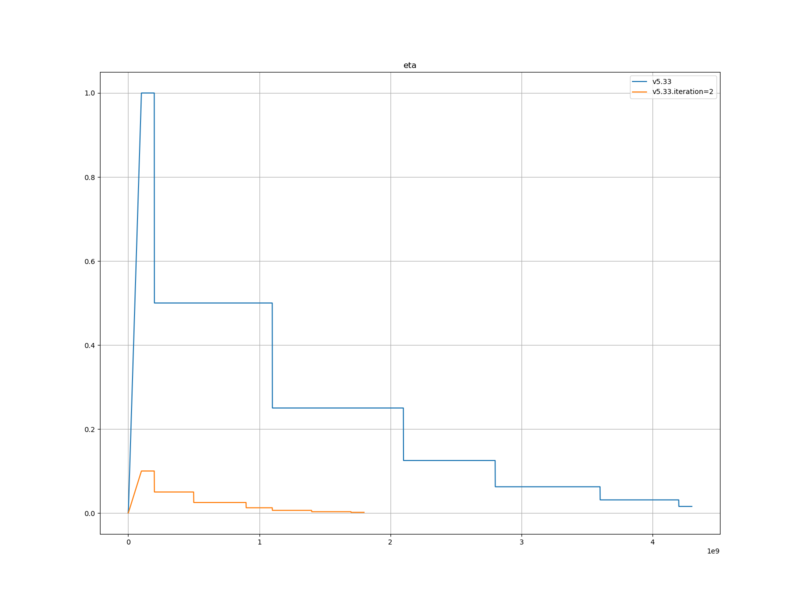
| eta | eta1=1e-8 eta2=0.1 eta1_epoch=100 (eta2 を 1.0 に設定したところ、まったくロスが下がらなかった) |
| newbob_decay | 0.5 |
| nn_batch_size | 1000 |
| eval_save_interval | 100000000 |
| loss_output_interval | 1000000 |
| mirror_percentage | 50 |
| eval_limit | 32000 |
| weight_by_progress | 無効 |
| 次元下げ | K・P・相対KP |
| 学習データ内で重複した局面の除外 | しない |
| 初期ネットワークパラメーター | https://docs.google.com/document/d/1Lup-hHFH2_QWqEfe56obJ6OEwj15P-C0VO6pWV9-vgo/edit?usp=sharing やねうら王 V5.33 で作成した評価関数 |
| 勝敗項の教師信号 | 1.0 |
| やねうら王バージョン | V5.33 相当 |
レーティング測定
| 対局相手 | https://docs.google.com/document/d/1Lup-hHFH2_QWqEfe56obJ6OEwj15P-C0VO6pWV9-vgo/edit?usp=sharing やねうら王 V5.33 で作成した評価関数 |
| 思考時間 | 持ち時間 300 秒 + 1 手 2 秒加算 |
| 対局数 | 5000 |
| 同時対局数 | 64 |
| ハッシュサイズ | 768 |
| 開始局面 | たややん互換局面集 |
実験結果
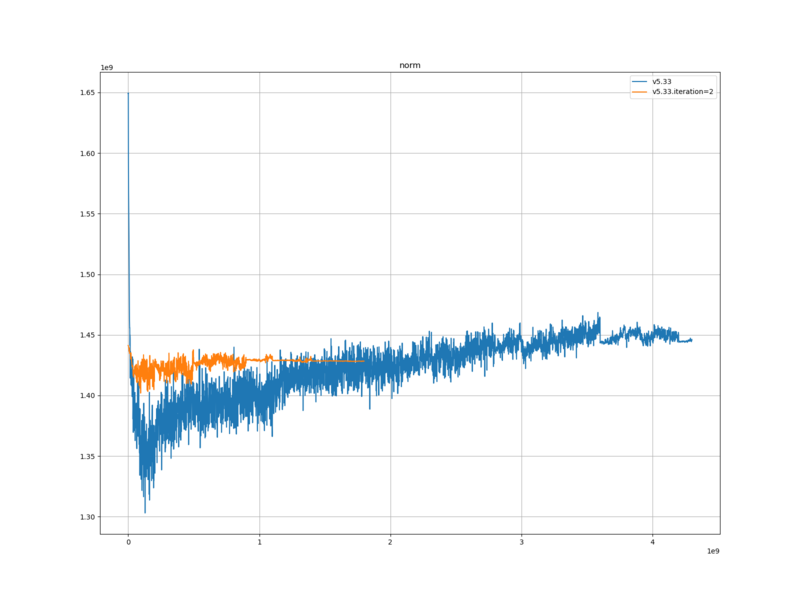
機械学習
v5.33 … 学習データの生成に使用した評価関数を学習した際の記録
v5.33.iteration=2 … 今回作成した評価関数を学習した際の記録
レーティング測定
対局数=5000 同時対局数=64 ハッシュサイズ=768 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\TanukiColiseum\taya36_2020-11-06.sfen NUMAノード数=2 表示更新間隔(ms)=3600000
思考エンジン1 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine1\source\YaneuraOu-by-gcc.exe 評価関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33.iteration=2\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale1=20
思考エンジン2 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine2\source\YaneuraOu-by-gcc.exe 評価関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale2=20
対局数5000 先手勝ち2178(53.1%) 後手勝ち1922(46.9%) 引き分け900
engine1
勝ち1994(48.6% R-7.8 +-9.6) 先手勝ち1070(26.1%) 後手勝ち924(22.5%)
宣言勝ち199 先手宣言勝ち107 後手宣言勝ち92 先手引き分け431 後手引き分け469
engine2
勝ち2106(51.4%) 先手勝ち1108(27.0%) 後手勝ち998(24.3%)
宣言勝ち94 先手宣言勝ち47 後手宣言勝ち47 先手引き分け469 後手引き分け431
1994,900,2106
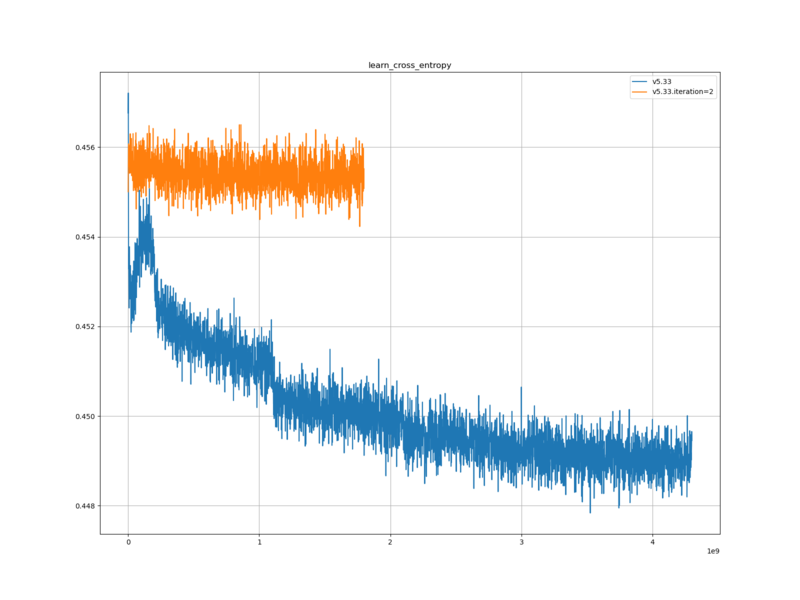
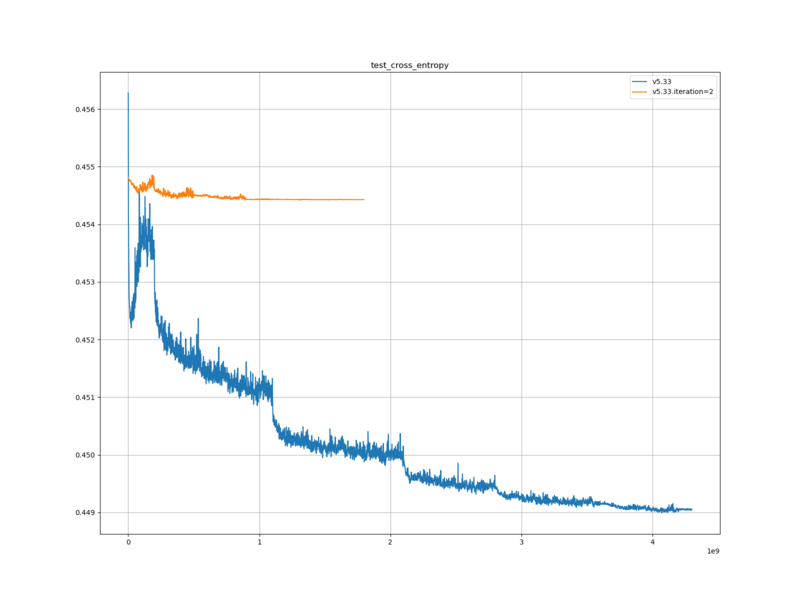
学習ロスと検証ロスは、元の評価関数に比べて、大きかった。また、元の評価関数に比べて、下がり幅が小さかった。
平手局面の評価値は、元の評価関数に比べて、ほとんど変わらなかった。
評価値の絶対値は、元の評価関数と比べて、やや小さかった。
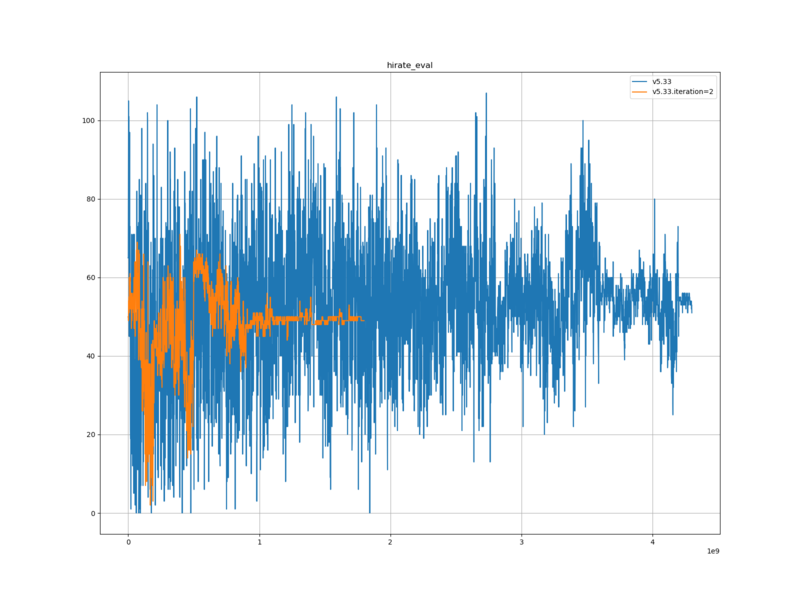
レーティングは、元の評価関数と比べて R-7.8 低かったが、有意差はなかった。
考察
学習ロスと検証ロスが、元の評価関数と異なっている点については、学習データが異なるため、自然なことだと考える。
また、元の評価関数より大きかった点については、今回の学習データと、評価関数の出力との相互エントロピーが大きいという事であるので、評価関数が学習データから学習できた部分が少ないという事なのだと思われる。おそらく halfkp_256x2-32-32 の表現能力の限界に到達してしてしまっているのだと思われる。
平手局面の評価値については、学習に大きな問題が発生しなかったという事を表しているものと思われる。
評価値の絶対値については、今回使用した学習データのほうが、評価値の絶対値が小さい局面の割合が大きいという事なのだと思われる。
レーティングについては、学習ロスと検証ロスと同様、 halfkp_256x2-32-32 の表現能力の限界に到達してしまっているのだと思われる。現在の表現能力のままレーティングを上げるためには、ネットワークパラメーターを、将棋の勝敗に直結する局面に対する解像度を上げる方向に割り当てる必要があると思われる。このためには、学習データに、そのような局面、および周辺の局面を多く含められるような、学習データ生成手法・パラメーターが必要だと思われる。
まとめ
「tanuki- 2022-06-07 やねうら王学習部リグレッション調査」で作成した評価関数が思いのほか強かったので、そこからの強化学習を行い、レーティングの変化を測定した。
結果、レーティングは向上しなかった。学習データ生成手法・パラメーターの改善が必要だと思われる。