tanuki- 2022-07-12 教師局面生成時の開始局面 (s-book_black)
実験内容
- 教師局面の生成時、開始局面として s-book_black に収録されている局面を使用し、学習した評価関数のレーティングを計測する。
棋譜生成
| 生成ルーチン | tanuki-棋譜生成ルーチン |
| 評価関数 | 水匠 5 FV_SCALE=16 |
| 1手あたりの思考 | 深さ最大 9 思考ノード数最大 50,000 ノード |
| 開始局面 | 1. foodgate の 2020 年~ 2021 年の棋譜のうち、レーティング 3900 以上同士の対局の 32 手目までから 1 局面ランダムに選択し、その局面を開始局面とした 2. s-book_black |
| 開始局面後のランダムムーブ | なし |
| 生成局面数 | 1. 10 億局面 × 8 セット 2. 10 億局面 × 1 セット 1. と 2. を混ぜた |
| 生成条件 | 対局は打ち切らず詰みの局面まで学習データに出力した |
機械学習
| 機械学習ルーチン | やねうら王機械学習ルーチン |
| 学習モデル | halfkp_256x2-32-32 |
| 学習手法 | SGD ミニバッチ法 |
| USI_Hash | 1024 |
| Threads | 127 |
| loop | 100 |
| batchsize | 1000000 |
| lambda | 0.5 |
| eta | eta1=1e-8 eta2=0.1 eta1_epoch=100 |
| newbob_decay | 0.5 |
| nn_batch_size | 1000 |
| eval_save_interval | 100000000 |
| loss_output_interval | 1000000 |
| mirror_percentage | 50 |
| eval_limit | 32000 |
| weight_by_progress | 無効 |
| 次元下げ | K・P・相対KP |
| 学習データ内で重複した局面の除外 | しない |
| 初期ネットワークパラメーター | tanuki-wcsc29 |
| 勝敗項の教師信号 | 1.0 |
| やねうら王バージョン | V5.33 相当 |
レーティング測定
| 対局相手 | https://docs.google.com/document/d/1Lup-hHFH2_QWqEfe56obJ6OEwj15P-C0VO6pWV9-vgo/edit?usp=sharing やねうら王 V5.33 で作成した評価関数 |
| 思考時間 | 持ち時間 300 秒 + 1 手 2 秒加算 |
| 対局数 | 5000 |
| 同時対局数 | 64 |
| ハッシュサイズ | 768 |
| 開始局面 | たややん互換局面集 |
実験結果
機械学習
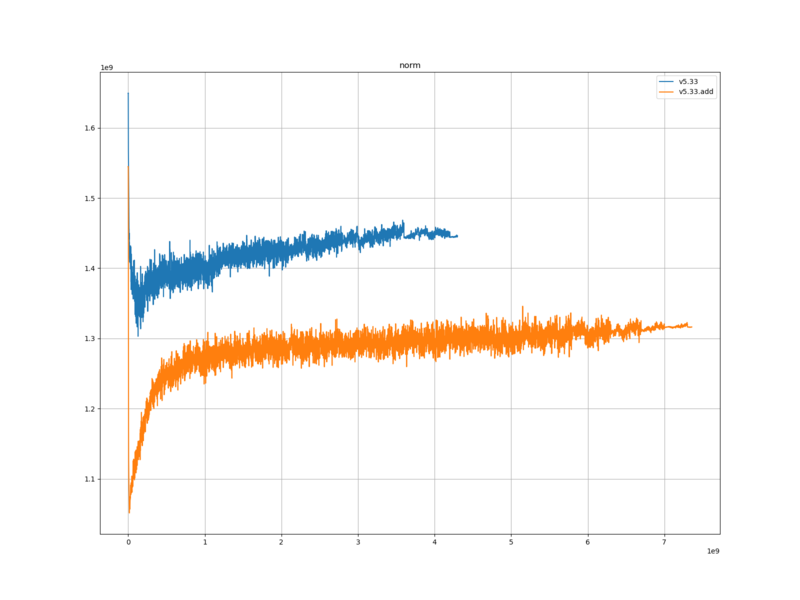
v5.33 … https://docs.google.com/document/d/1Lup-hHFH2_QWqEfe56obJ6OEwj15P-C0VO6pWV9-vgo/edit?usp=sharing
v5.33.add … 今回作成した評価関数を学習した際の記録
レーティング測定
対局数=5000 同時対局数=64 ハッシュサイズ=768 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\TanukiColiseum\taya36_2020-11-06.sfen NUMAノード数=2 表示更新間隔(ms)=3600000
思考エンジン1 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine1\source\YaneuraOu-by-gcc.exe 評価関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33.add.s-book_black\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale1=20
思考エンジン2 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine2\source\YaneuraOu-by-gcc.exe 評価関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale2=20
対局数5000 先手勝ち2328(53.5%) 後手勝ち2024(46.5%) 引き分け648
engine1
勝ち1395(32.1% R-112.3 +-10.1) 先手勝ち766(17.6%) 後手勝ち629(14.5%)
宣言勝ち84 先手宣言勝ち43 後手宣言勝ち41 先手引き分け338 後手引き分け310
engine2
勝ち2957(67.9%) 先手勝ち1562(35.9%) 後手勝ち1395(32.1%)
宣言勝ち85 先手宣言勝ち37 後手宣言勝ち48 先手引き分け310 後手引き分け338
1395,648,2957
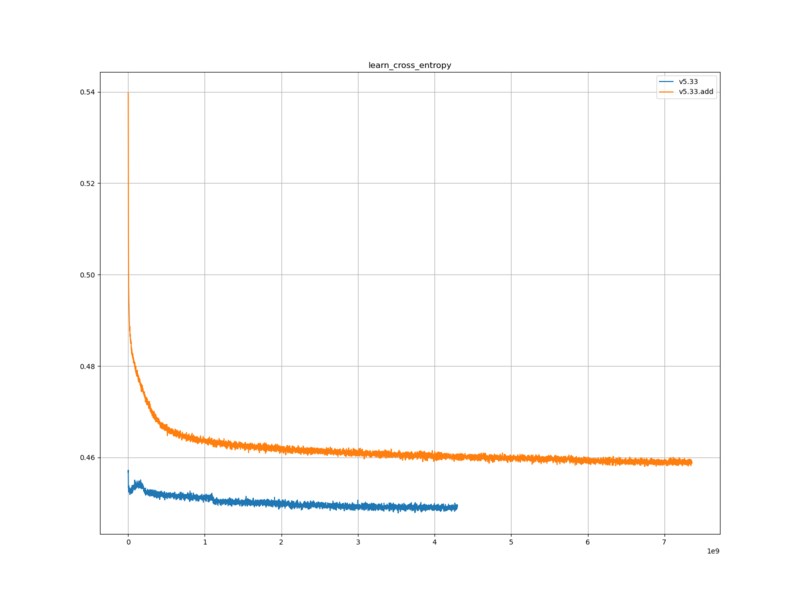
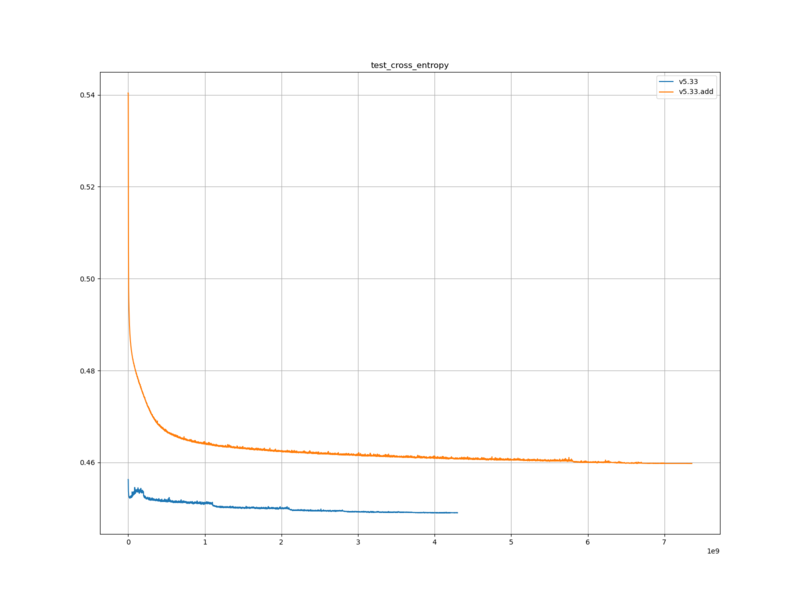
学習ロスと検証ロスは、元の評価関数に比べて、大きかった。
平手局面の評価値は、元の評価関数に比べて、ほとんど変わらなかった。
評価値の絶対値は、元の評価関数と比べて、小さかった。
レーティングは、ベースラインとした評価関数と比べて、 R-112.3 程度低かった。
考察
学習ロスと検証ロスについては、ロスの定義が交差エントロピーであることを考えると、 s-book_black の各局面を開始局面にした教師局面を加えたことによって、評価値的に互角に近い局面が増えたのだと思われる。
平手局面の評価値については、学習に大きな問題が発生しなかったという事を表しているものと思われる。
評価値の絶対値については、教師局面に、評価値的に互角に近い局面が増えたのだと思われる。これは、学習ロスと検証ロスの考察結果と矛盾はない。
レーティングについては、いくつか原因が考えられる。一つは、 s-book_black に収録されている局面に、過学習してしまっている可能性である。これにより、たややん互換局面集を用いた対局で、レーティングが下がってしまった可能性がある。もう一つは、学習器の問題である。この実験の前後に、やねうら王学習器に対して、いくつかの変更を施した。これが意図せず revert されず、レーティングの低下を引き起こしている可能性がある。
まとめ
教師局面の生成時、開始局面として s-book_black に収録されている局面を使用し、学習した評価関数のレーティングを計測した。結果、ベースラインとした評価関数と比べて、 R-112.3 程度低かった。
やねうら王に加えた変更が、レーティングの低下を引き起こしていないかどうか、追試を行いたい。