-
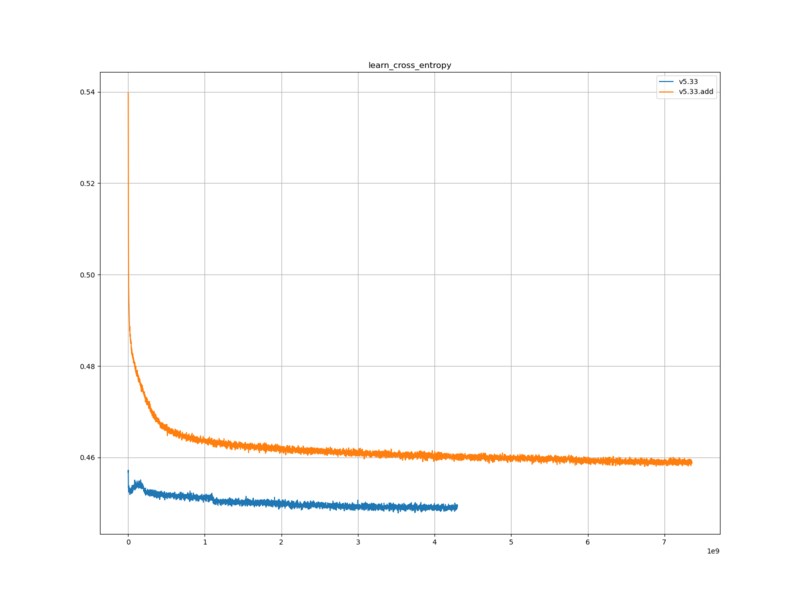
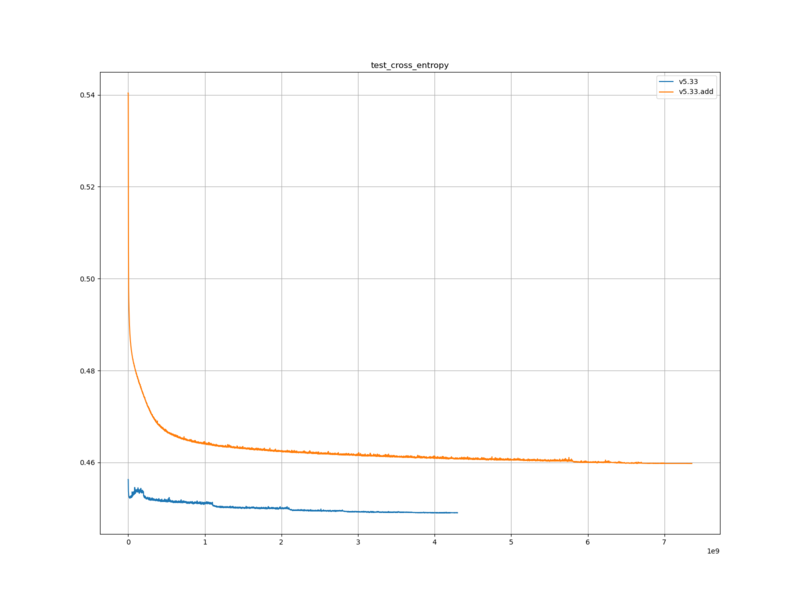
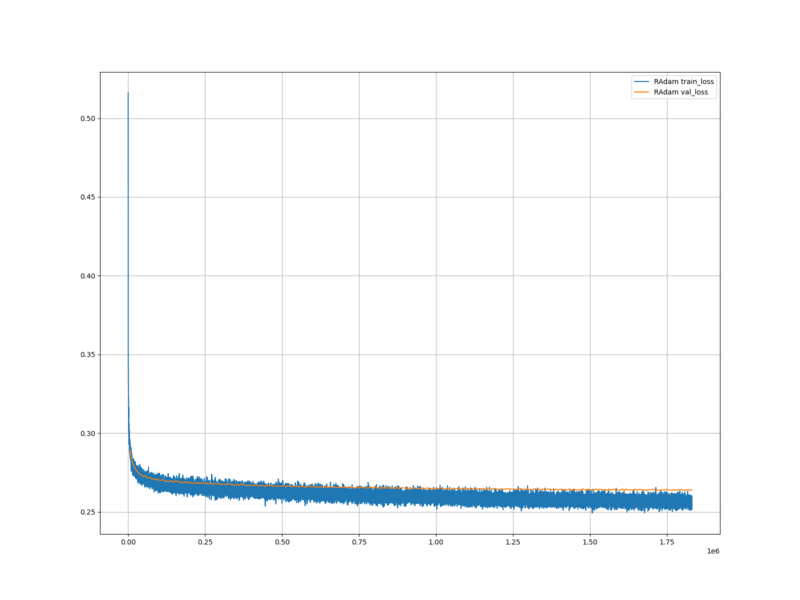
水匠 5 を用いて生成した学習データを用いて学習した評価関数で、 FV_SCALE の値を変化させたときの、レーティングの変化を調べる。
-
水匠 5 が、 FV_SCALE を変化させることでレーティングが変化するのであれば、それを用いて学習させた評価関数も、同様のことが起こるのではないかと予想した。
|
生成ルーチン
|
tanuki-棋譜生成ルーチン
|
|
評価関数
|
水匠5
FV_SCALE=16
|
|
1手あたりの思考
|
深さ最大 9
思考ノード数最大 50,000 ノード
|
|
開始局面
|
foodgate の 2020 年~ 2021 年の棋譜のうち、レーティング 3900 以上同士の対局の 32 手目までから 1 局面ランダムに選択し、その局面を開始局面とした
ランダムムーブなし
|
|
生成局面数
|
10 億局面 × 8 セット
|
|
生成条件
|
対局は打ち切らず詰みの局面まで学習データに出力した
|
|
機械学習ルーチン
|
やねうら王機械学習ルーチン
|
|
学習モデル
|
halfkp_256x2-32-32
|
|
学習手法
|
SGD
ミニバッチ法
|
|
USI_Hash
|
1024
|
|
Threads
|
64
|
|
loop
|
100
|
|
batchsize
|
1000000
|
|
lambda
|
0.5
|
|
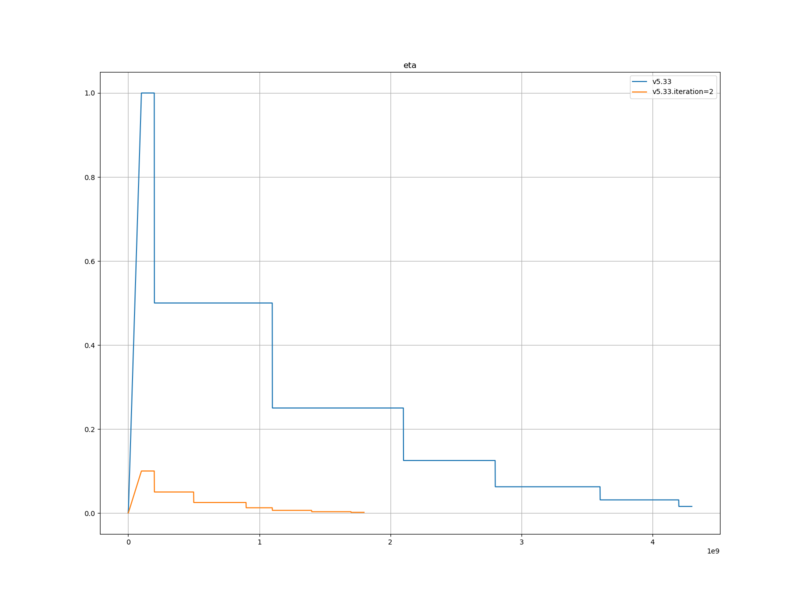
eta
|
eta1=1e-8 eta2=1.0 eta1_epoch=100
|
|
newbob_decay
|
0.5
|
|
nn_batch_size
|
1000
|
|
eval_save_interval
|
100000000
|
|
loss_output_interval
|
1000000
|
|
mirror_percentage
|
50
|
|
eval_limit
|
32000
|
|
weight_by_progress
|
無効
|
|
次元下げ
|
K・P・相対KP
|
|
学習データ内で重複した局面の除外
|
バージョンのデフォルトに依存する
|
|
初期ネットワークパラメーター
|
tanuki-wcsc29
|
|
勝敗項の教師信号
|
1.0
|
|
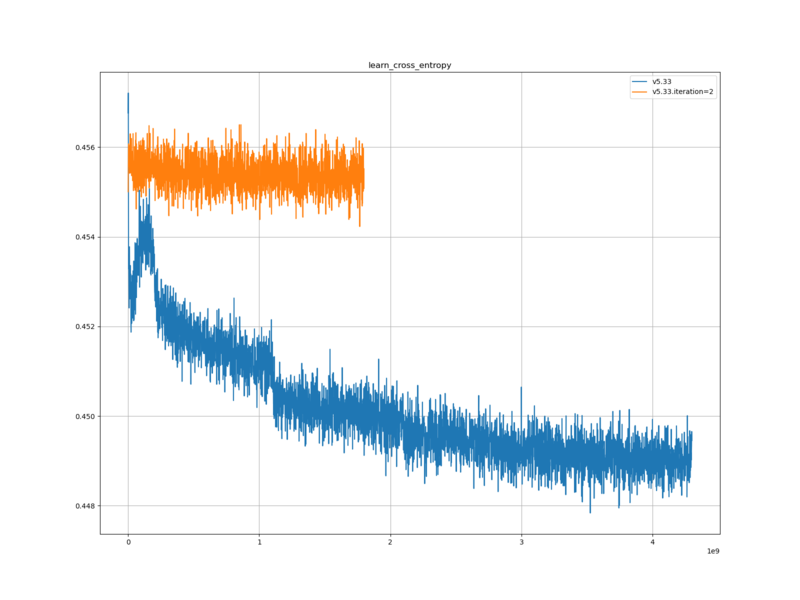
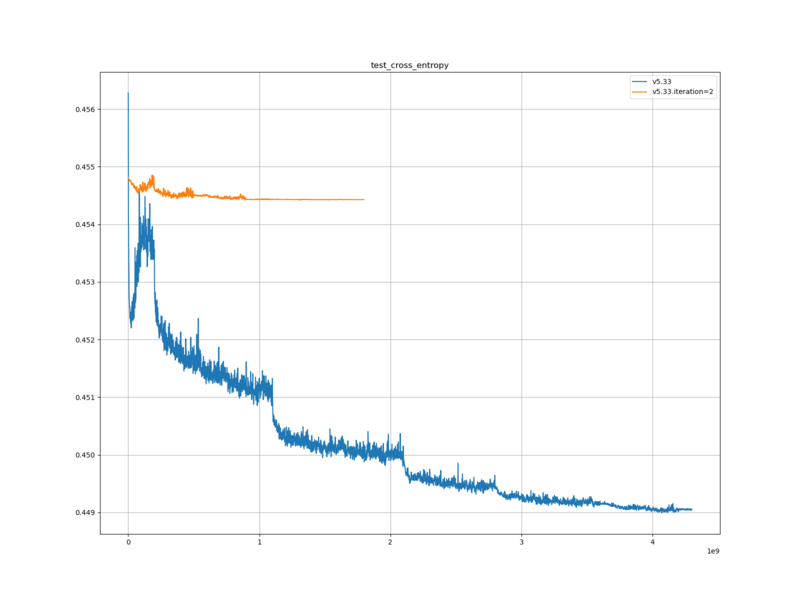
やねうら王バージョン
|
V5.33
|
レーティング測定
|
対局相手
|
tanuki-wcsc32-2022-05-06
|
|
思考時間
|
持ち時間 300 秒 + 1 手 2 秒加算
|
|
対局数
|
2000
|
|
同時対局数
|
64
|
|
ハッシュサイズ
|
768
|
|
開始局面
|
たややん互換局面集
|
実験結果
https://docs.google.com/document/d/1Lup-hHFH2_QWqEfe56obJ6OEwj15P-C0VO6pWV9-vgo/edit?usp=sharing
に掲載されているものと同じ。
レーティング測定
対局数=2000 同時対局数=64 ハッシュサイズ=640 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\TanukiColiseum\taya36_2020-11-06.sfen NUMAノード数=2 表示更新間隔(ms)=3600000
思考エンジン1 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine1\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させ
る=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale1=16
思考エンジン2 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine2\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\tanuki-wcsc32-2022-05-06\eval 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale2=16
対局数2000 先手勝ち906(50.7%) 後手勝ち881(49.3%) 引き分け213
engine1
勝ち923(51.7% R10.3 +-15.2) 先手勝ち470(26.3%) 後手勝ち453(25.3%)
宣言勝ち43 先手宣言勝ち24 後手宣言勝ち19 先手引き分け103 後手引き分け110
engine2
勝ち864(48.3%) 先手勝ち436(24.4%) 後手勝ち428(24.0%)
宣言勝ち2 先手宣言勝ち0 後手宣言勝ち2 先手引き分け110 後手引き分け103
923,213,864
対局数=2000 同時対局数=64 ハッシュサイズ=640 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\TanukiColiseum\taya36_2020-11-06.sfen NUMAノード数=2 表示更新間隔(ms)=3600000
思考エンジン1 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine1\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させ
る=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale1=20
思考エンジン2 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine2\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\tanuki-wcsc32-2022-05-06\eval 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale2=16
対局数2000 先手勝ち908(51.7%) 後手勝ち849(48.3%) 引き分け243
engine1
勝ち932(53.0% R18.6 +-15.3) 先手勝ち481(27.4%) 後手勝ち451(25.7%)
宣言勝ち53 先手宣言勝ち27 後手宣言勝ち26 先手引き分け121 後手引き分け122
engine2
勝ち825(47.0%) 先手勝ち427(24.3%) 後手勝ち398(22.7%)
宣言勝ち1 先手宣言勝ち1 後手宣言勝ち0 先手引き分け122 後手引き分け121
932,243,825
対局数=2000 同時対局数=64 ハッシュサイズ=640 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\TanukiColiseum\taya36_2020-11-06.sfen NUMAノード数=2 表示更新間隔(ms)=3600000
思考エンジン1 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine1\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させ
る=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale1=24
思考エンジン2 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine2\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\tanuki-wcsc32-2022-05-06\eval 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale2=16
対局数2000 先手勝ち885(51.3%) 後手勝ち840(48.7%) 引き分け275
engine1
勝ち855(49.6% R-2.6 +-15.2) 先手勝ち435(25.2%) 後手勝ち420(24.3%)
宣言勝ち43 先手宣言勝ち29 後手宣言勝ち14 先手引き分け140 後手引き分け135
engine2
勝ち870(50.4%) 先手勝ち450(26.1%) 後手勝ち420(24.3%)
宣言勝ち2 先手宣言勝ち1 後手宣言勝ち1 先手引き分け135 後手引き分け140
855,275,870
対局数=2000 同時対局数=64 ハッシュサイズ=640 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\TanukiColiseum\taya36_2020-11-06.sfen NUMAノード数=2 表示更新間隔(ms)=3600000
思考エンジン1 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine1\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させ
る=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale1=28
思考エンジン2 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine2\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\tanuki-wcsc32-2022-05-06\eval 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale2=16
対局数2000 先手勝ち938(54.0%) 後手勝ち799(46.0%) 引き分け263
engine1
勝ち803(46.2% R-22.8 +-15.3) 先手勝ち427(24.6%) 後手勝ち376(21.6%)
宣言勝ち42 先手宣言勝ち22 後手宣言勝ち20 先手引き分け149 後手引き分け114
engine2
勝ち934(53.8%) 先手勝ち511(29.4%) 後手勝ち423(24.4%)
宣言勝ち4 先手宣言勝ち1 後手宣言勝ち3 先手引き分け114 後手引き分け149
803,263,934
対局数=2000 同時対局数=64 ハッシュサイズ=640 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\TanukiColiseum\taya36_2020-11-06.sfen NUMAノード数=2 表示更新間隔(ms)=3600000
思考エンジン1 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine1\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\shogi\eval\regression.v5.33\final 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させ
る=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale1=32
思考エンジン2 name=YaneuraOu NNUE 7.10 64ZEN2 TOURNAMENT author=by yaneurao exeファイル=C:\Jenkins\workspace\TanukiColiseum.2022-05-02\engine2\source\YaneuraOu-by-gcc.exe 評価
関数フォルダパス=D:\hnoda\tanuki-wcsc32-2022-05-06\eval 定跡手数=256 定跡ファイル名=no_book 思考ノード数=0 思考ノード数に加える乱数(%)=0 思考ノード数の乱数を1手毎に変化させる=False 持ち時間(ms)=300000 秒読み時間(ms)=0 加算時間(ms)=2000 乱数付き思考時間(ms)=0 スレッド数=1 BookEvalDiff=30 定跡の採択率を考慮する=false 定跡の手数を無視する=false SlowMover=100 DrawValue=-2 BookEvalBlackLimit=0 BookEvalWhiteLimit=-140 FVScale2=16
対局数2000 先手勝ち954(54.2%) 後手勝ち807(45.8%) 引き分け239
engine1
勝ち808(45.9% R-25.2 +-15.3) 先手勝ち434(24.6%) 後手勝ち374(21.2%)
宣言勝ち47 先手宣言勝ち19 後手宣言勝ち28 先手引き分け132 後手引き分け107
engine2
勝ち953(54.1%) 先手勝ち520(29.5%) 後手勝ち433(24.6%)
宣言勝ち2 先手宣言勝ち2 後手宣言勝ち0 先手引き分け107 後手引き分け132
808,239,953
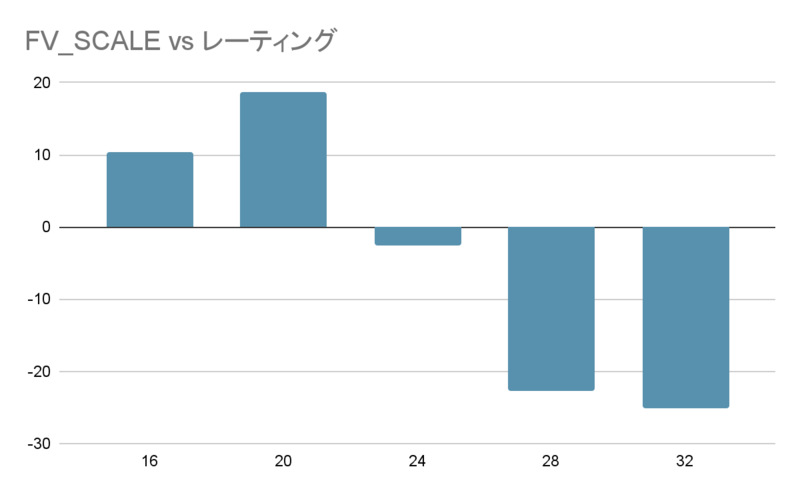
FV_SCALE=20 のときに、最もレーティングが高くなった。また、 FV_SCALE=20 から離れるほど、レーティングは下がっていった。
考察
水匠 5 同様、水匠 5 の学習データを元に学習させた評価関数も、 FV_SCALE を調整する事により、レーティングを伸ばすことができるのだと思われる。ただし、教師信号の勝敗項の勝率を調整した場合、評価値のスケールが変化するため、この限りではない可能性がある。
まとめ
水匠 5 を用いて生成した学習データを用いて学習した評価関数で、 FV_SCALE の値を変化させたときの、レーティングの変化を調べた。結果、今回実験に使用した評価関数については、 FV_SCALE=20 のときに、最もレーティングが高くなった。今後評価関数を大会で使用する際は、直前に、最適な FV_SCALE の値を調べたい。