tanuki- 2024-12-17 大森さんのブランチ
実験内容
- 氷彗開発者大森さんのブランチを試す。
- 学習器には https://github.com/saihyou/nnue-pytorch/tree/feature/layer_stack_1536 に、自分のブランチの内容をマージしたものを使用する。
- 思考エンジンには https://github.com/saihyou/YaneuraOu/tree/feature/layer_stack を halfka_1536-15-64 に対応させたものを使用する。
棋譜生成
ランダムパラメーターから学習させる際の学習データ
| 生成ルーチン | tanuki-棋譜生成ルーチン |
| 評価関数 | tanuki-.nnue-pytorch-2024-07-30.1 |
| 1手あたりの思考 | 深さ最大 9 思考ノード数最大 50,000 ノード |
| 開始局面 | foodgate の 2020 年~ 2021 年の棋譜を使用した。レーティング 3900 以上同士の対局のみ使用した。戦型が角換わりの対局が 10% になるよう調整した。 32 手目までから 1 局面ランダムに選択し、その局面を開始局面とした。ランダムムーブはしなかった。 |
| 生成局面数 | 10 億局面 × 8 セット |
| 生成条件 | 対局は打ち切らず詰みの局面まで学習データに出力した |
| フォルダ名 | tanuki-.nnue-pytorch-2024-07-30.1 |
シャッフル条件
ランダムパラメータから学習させる際の学習データ
| 生成ルーチン | tanuki-シャッフルルーチン |
| qsearch() | あり |
| 置換表 | 無効 |
| min_progress | 0.0 |
Fine-tuning に用いる学習データ
| 生成ルーチン | tanuki-シャッフルルーチン |
| qsearch() | あり |
| 置換表 | 無効 |
| min_progress | 0.1 |
機械学習
| 機械学習ルーチン | nnue-pytorch + やねうら王 https://github.com/nodchip/nnue-pytorch/tree/shogi.2024-12-08.hisui |
| 学習モデル | halfka_1536-15-64 |
| 学習手法 | ミニバッチ SGD |
| 初期学習率 (lr) | 0.5 収束後 0.05 |
| 最適化手法 | なし |
| 学習率調整手法 | Warmup + Newbob 風 |
| batch-size | 16384 |
| threads | 8 |
| num-workers | 8 |
| accelerator | gpu |
| devices | 1 |
| features | HalfKP |
| max-epoch | 1000000 |
| score-scaling | 511 |
| lambda | 1.0 収束後 60 手目までは手数に応じて lambda を 1.0 から 0.0 まで線形に下げる。 60 手目以降は 0.0 とする。 |
| 勝敗項の教師信号 | 1.0 - 1e-8 |
| num-batches-warmup | 10000 |
| newbob-decay | 0.5 |
| epoch-size | 1000000 |
| num-epochs-to-adjust-lr | 500 |
| 学習を打ち切る下限 newbob scale | 1e-5 |
| 1 epoch 毎のネットワークパラメーターのクリップ | あり |
| ネットワークパラメーターの量子化 | 量子化なしで学習し、収束後に量子化する。 |
| ネットワークパラメーターの初期化方法 | pytorch のデフォルトの初期化手法で初期化する。 |
| 勾配の正規化 | なし |
| momentum | 0.9 |
| 入玉ボーナス | 入玉時、持ち駒および敵陣三段目までに侵入している駒について、小駒 1 枚につき 20 点、大駒 1 枚につき 100 点、敵陣三段目までに侵入している駒 1 枚につき 20 点追加する。 |
レーティング測定
| 対局相手 | https://docs.google.com/document/d/1rTkwx-9YFiHwtHdzN8EMcNA1ZhP-kLi95e9xQ9tDyWs/edit?usp=sharing tanuki-.nnue-pytorch-2024-11-22.0 |
| 思考時間 | 持ち時間 300 秒 + 1 手 2 秒加算 |
| 対局数 | 5000 |
| 同時対局数 | 64 |
| ハッシュサイズ | 384 |
| 開始局面 | dlshogi 互角局面集の角換わりの割合が 10% になるよう間引いたもの |
実験結果
機械学習
ランダムパラメーターからの学習
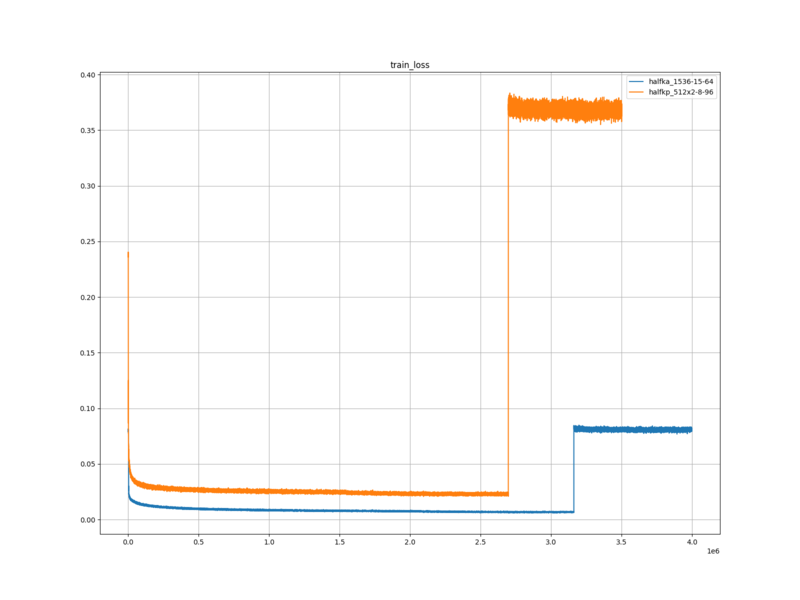
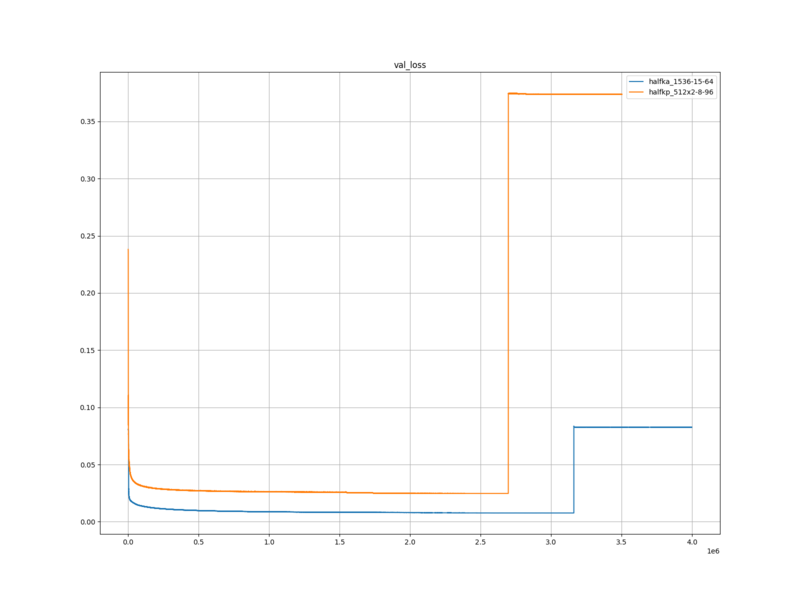
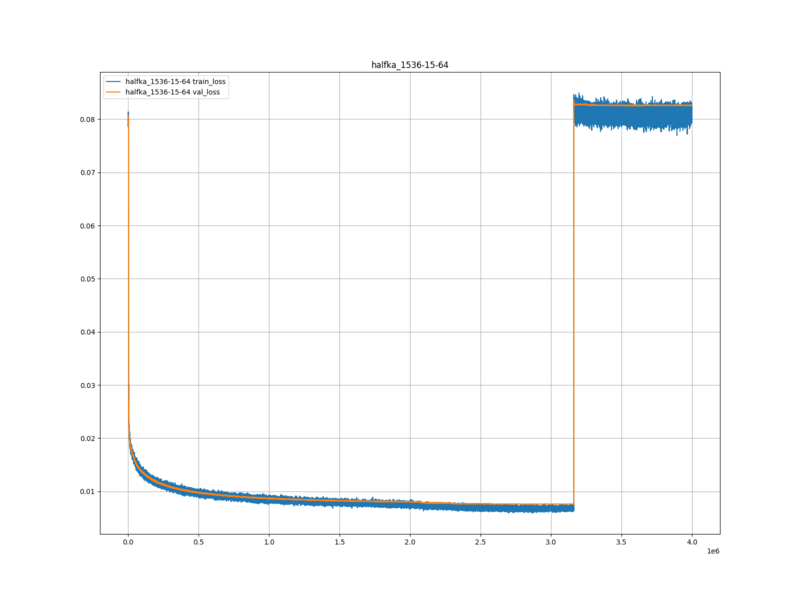
検証ロス
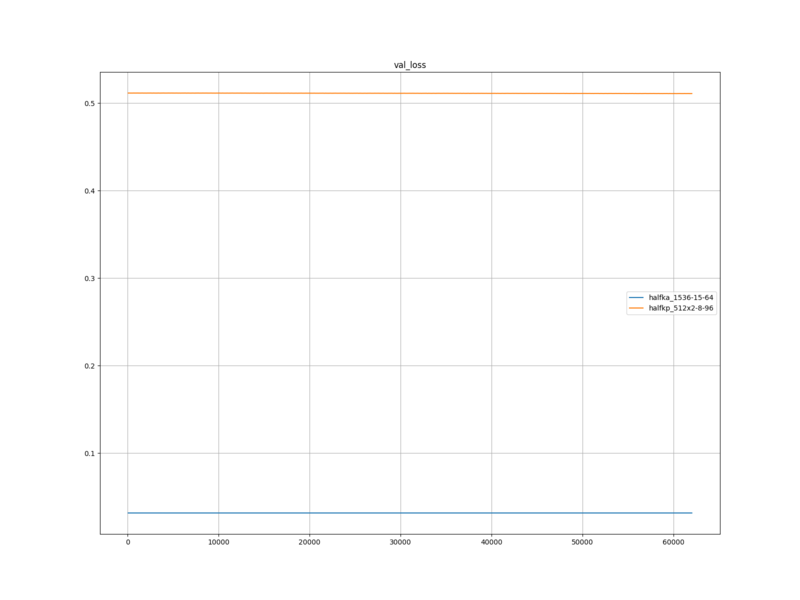
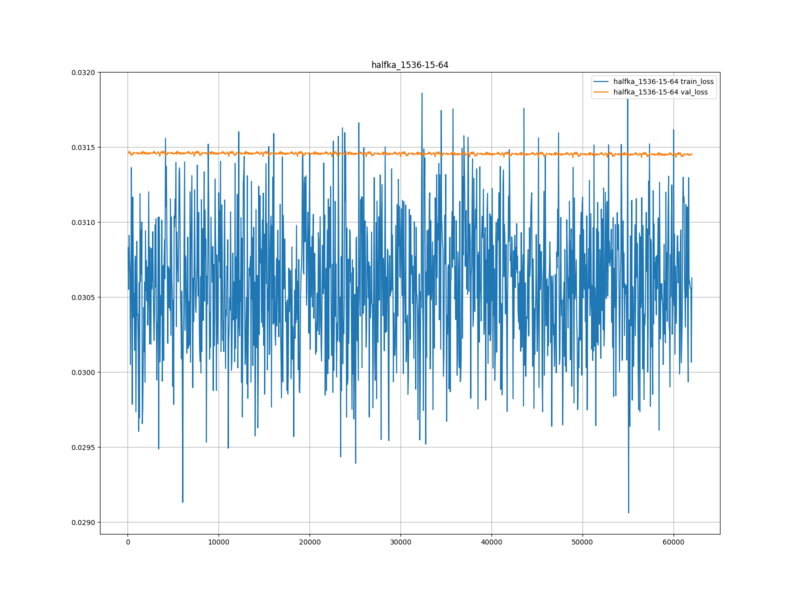
HalfKP+Mobility … 0.08258476575728385
halfkp_512x2-8-96 … 0.3736974278111612
Fine-tuning
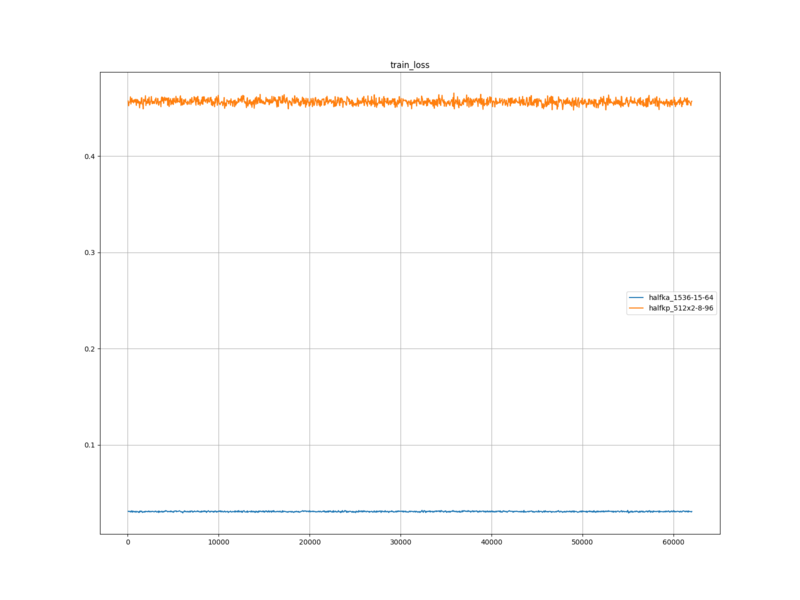
レーティング測定
対局数=5000 同時対局数=64 ハッシュサイズ=384 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2023-04-16\TanukiColiseum\floodgate32-80.adjust_bishop_exchange.sfen NUMAノード数=1 表示更新間隔(ms)=3600000
思考エンジン1 思考エンジン2
name YaneuraOu NNUE 8.30git 64ZEN2 TOURNAMENT YaneuraOu NNUE 8.30git 64ZEN2 TOURNAMENT
author by yaneurao by yaneurao
exeファイル C:\Jenkins\workspace\TanukiColiseum.2023-04-16\engine1\source\YaneuraOu-by-gcc.exe C:\Jenkins\workspace\TanukiColiseum.2023-04-16\engine2\source\YaneuraOu-by-gcc.exe
評価関数フォルダパス D:\hnoda\shogi\eval\tanuki-.nnue-pytorch-2024-12-08.0 D:\hnoda\shogi\eval\tanuki-.nnue-pytorch-2024-11-22.0
定跡手数 256 256
定跡ファイル名 no_book no_book
思考ノード数 0 0
思考ノード数に加える乱数(%) 0 0
思考ノード数の乱数を1手毎に変化させる False False
持ち時間(ms) 300000 300000
秒読み時間(ms) 0 0
加算時間(ms) 2000 2000
乱数付き思考時間(ms) 0 0
スレッド数 1 1
BookEvalDiff 30 30
定跡の採択率を考慮する true true
定跡の手数を無視する true true
SlowMover 100 100
DrawValue -2 -2
BookEvalBlackLimit 0 0
BookEvalWhiteLimit -140 -140
FVScale 16 16
Depth=0 0
MinimumThinkingTime 1000 1000
対局数5000 先手勝ち2505(52.9%) 後手勝ち2226(47.1%) 引き分け269
engine1
勝ち808(17.1% R-253.6 +-12.3) 先手勝ち463(9.8%) 後手勝ち345(7.3%)
宣言勝ち28 先手宣言勝ち16 後手宣言勝ち12 先手引き分け155 後手引き分け114
engine2
勝ち3923(82.9%) 先手勝ち2042(43.2%) 後手勝ち1881(39.8%)
宣言勝ち12 先手宣言勝ち7 後手宣言勝ち5 先手引き分け114 後手引き分け155
808,269,3923
対局数=5000 同時対局数=64 ハッシュサイズ=384 開始手数=24 最大手数=320 開始局面ファイル=C:\Jenkins\workspace\TanukiColiseum.2023-04-16\TanukiColiseum\floodgate32-80.adjust_bishop_exchange.sfen NUMAノード数=1 表示更新間隔(ms)=3600000
思考エンジン1 思考エンジン2
name YaneuraOu NNUE 8.30git 64ZEN2 TOURNAMENT YaneuraOu NNUE 8.30git 64ZEN2 TOURNAMENT
author by yaneurao by yaneurao
exeファイル C:\Jenkins\workspace\TanukiColiseum.2023-04-16\engine1\source\YaneuraOu-by-gcc.exe C:\Jenkins\workspace\TanukiColiseum.2023-04-16\engine2\source\YaneuraOu-by-gcc.exe
評価関数フォルダパス D:\hnoda\shogi\eval\tanuki-.nnue-pytorch-2024-12-08.1 D:\hnoda\shogi\eval\tanuki-.nnue-pytorch-2024-11-22.0
定跡手数 256 256
定跡ファイル名 no_book no_book
思考ノード数 0 0
思考ノード数に加える乱数(%) 0 0
思考ノード数の乱数を1手毎に変化させる False False
持ち時間(ms) 300000 300000
秒読み時間(ms) 0 0
加算時間(ms) 2000 2000
乱数付き思考時間(ms) 0 0
スレッド数 1 1
BookEvalDiff 30 30
定跡の採択率を考慮する true true
定跡の手数を無視する true true
SlowMover 100 100
DrawValue -2 -2
BookEvalBlackLimit 0 0
BookEvalWhiteLimit -140 -140
FVScale 16 16
Depth=0 0
MinimumThinkingTime 1000 1000
対局数5000 先手勝ち2494(52.8%) 後手勝ち2227(47.2%) 引き分け279
engine1
勝ち795(16.8% R-255.4 +-12.4) 先手勝ち453(9.6%) 後手勝ち342(7.2%)
宣言勝ち19 先手宣言勝ち11 後手宣言勝ち8 先手引き分け160 後手引き分け119
engine2
勝ち3926(83.2%) 先手勝ち2041(43.2%) 後手勝ち1885(39.9%)
宣言勝ち16 先手宣言勝ち8 後手宣言勝ち8 先手引き分け119 後手引き分け160
795,279,3926
学習ロスと検証ロスは、ランダムパラメーターからの学習においても Fine-tuning においても、 tanuki-.nnue-pytorch-2024-11-22.0 より低くなった。
自己対局では、ランダムパラメーターから学習させたネットワークパラメーターは tanuki-.nnue-pytorch-2024-11-22.0 に対してレーティングが R253.6 低く、有意な差があった。 Fine-tuning したネットワークパラメーターは tanuki-.nnue-pytorch-2024-11-22.0 に対してレーティングが R255.4 低く、有意な差があった。
考察
学習ロスと検証ロスが、ランダムパラメーターからの学習においても Fine-tuning においても tanuki-.nnue-pytorch-2024-11-22.0 より低くなったのは、大森さんのブランチのロスの式が、 tanuki-.nnue-pytorch-2024-11-22.0 を学習させたときのロスの式と異なっているためだと思う。
自己対局で、ランダムパラメーターから学習させた評価関数と Fine-tuning した評価関数のレーティングに有意な差があった理由は、今回の実験からだけでは分からなかった。大森さんのブランチの変更を一つずつ revert し、どこで差ができたのかを調べる必要があると思う。
まとめ
氷彗開発者大森さんのブランチを試した。学習器には https://github.com/saihyou/nnue-pytorch/tree/feature/layer_stack_1536 に、自分のブランチの内容をマージしたものを使用した。思考エンジンには https://github.com/saihyou/YaneuraOu/tree/feature/layer_stack を halfka_1536-15-64 に対応させたものを使用した。
自己対局では、ランダムパラメーターから学習させたネットワークパラメーターは tanuki-.nnue-pytorch-2024-11-22.0 に対してレーティングが R253.6 低く、有意な差があった。 Fine-tuning したネットワークパラメーターは tanuki-.nnue-pytorch-2024-11-22.0 に対してレーティングが R255.4 低く、有意な差があった。
自己対局で、ランダムパラメーターから学習させた評価関数と Fine-tuning した評価関数のレーティングに有意な差があった理由は、今回の実験からだけでは分からなかった。大森さんのブランチの変更を一つずつ revert し、どこで差ができたのかを調べる必要があると思う。
tanuki-.nnue-pytorch-2024-07-30.1 の教師信号の評価値を、 DL 水匠の Value を評価値に変換したものに置き換え、学習させ、レーティングを計測したい。